
I am a fourth-year direct PhD student in the Department of Computer Science and Technology at Peking University (expected graduation in 2026). Before that, I obtained my undergraduate degree from the School of Electronics and Information Engineering at South China University of Technology in 2021.
📌 Research Interests
My research primarily focuses on the field of “Multimodal Large Language Models and Image/Video Understanding”, specifically including:
- Multimodal Large Language Model (video understanding), including:
- General video understanding: Qwen2.5-VL core contributor
- Audio-visual understanding: VideoLLaMA2; CMM
- Streaming video understanding: VideoLLaMA3
- Long video understanding: Inf-CL (CVPR 2025 Highlight)
- Fine-grained video understanding: VideoRefer (CVPR 2025)
- Image/video segmentation, including:
- Weakly supervised segmentation: OCR (CVPR 2023)
- Video instance segmentation: TAR (ICCV 2025)
- Multimodal segmentation: WiCo (IJCAI 2023, Neurocomputing 2024); PVD (AAAI 2024); BriVIS (AAAI 2025)
- Medical image segmentation: Fused U-Net (Medical Physics 2021)
📈 Academic Achievements
I have published over 20 papers, with a total of

The open-source projects I have participated in have received widespread attention, with the number of GitHub Stars for representative projects as follows:





💬 Contact Information
If you are interested in my research, please feel free to contact me for collaboration or to discuss internship/full-time opportunities 🙏🙏. My email address is: cyanlaser@stu.pku.edu.cn
🔥 News
- 2021.03: I join Sensetime
 as a research intern in shenzhen for developing MMSegmentation
as a research intern in shenzhen for developing MMSegmentation toolkit.
📝 Publications
🎞️ Multi-modal LLM (Video Understanding)
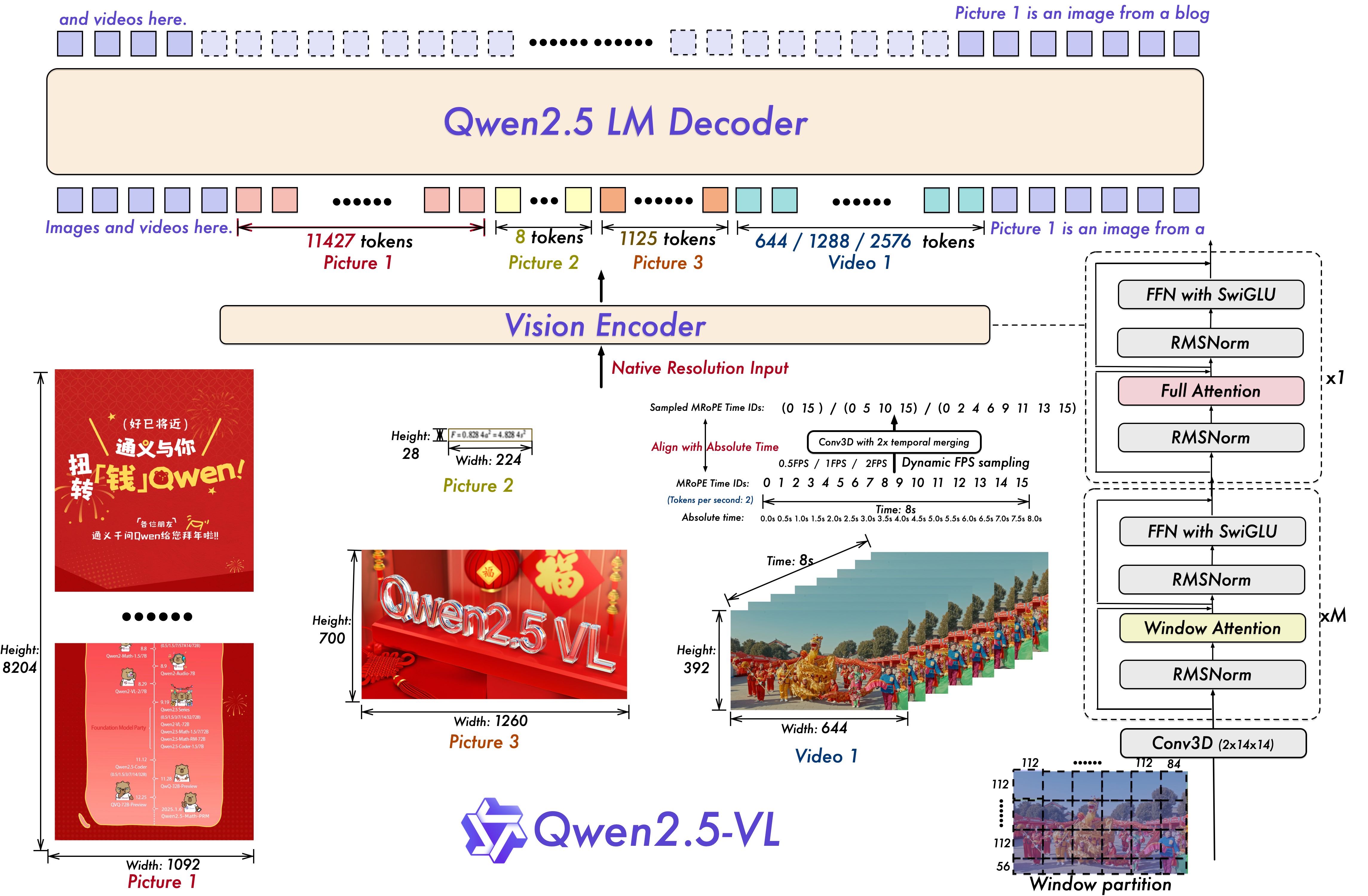
Qwen2.5-VL Technical Report
Core Contributors: Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, …, Zesen Cheng,
Hang Zhang, Zhibo Yang, Haiyang Xu, Junyang Lin

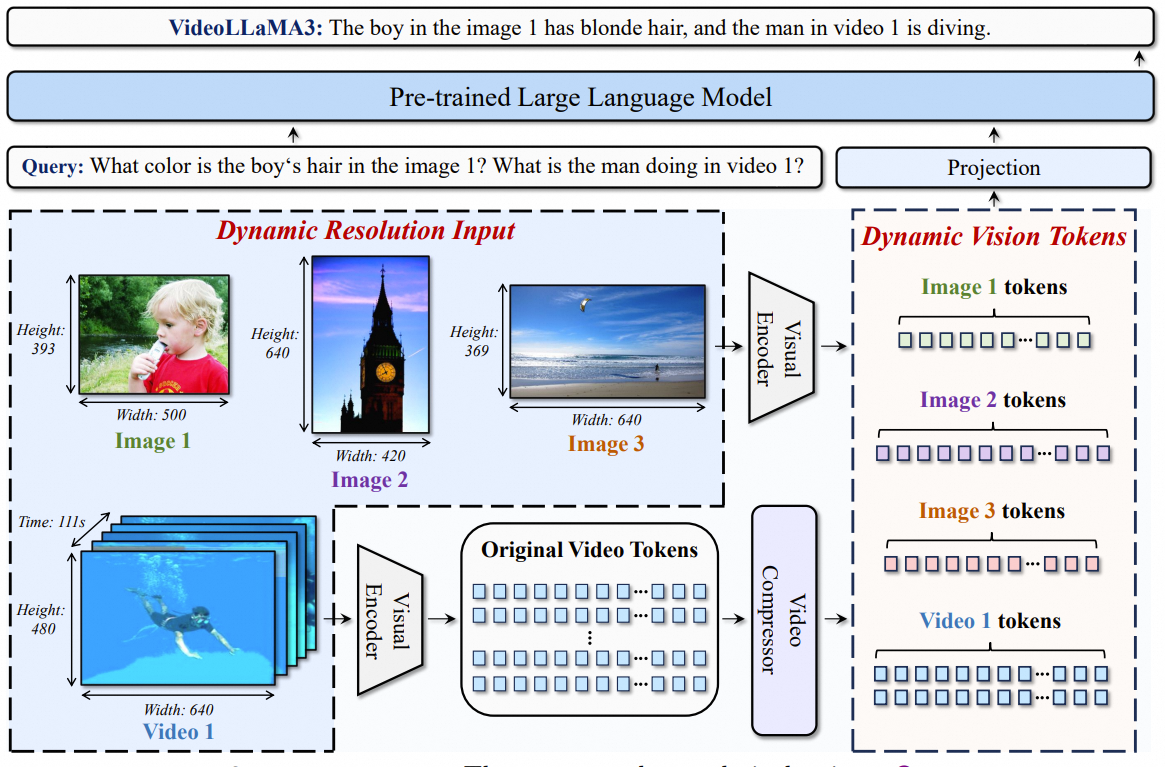
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Boqiang Zhang* Kehan Li*, Zesen Cheng*, Zhiqiang Hu*, Yuqian Yuan*, Guanzheng Chen*, Sicong Leng*, Yuming Jiang*, Hang Zhang*, Xin Li*, Peng Jin, Wenqi Zhang, Fan Wang, Lidong Bing, Deli Zhao
Code ![]() |
|
![]() |
|
![]()
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng*, Sicong Leng*, Hang Zhang*, Yifei Xin*, Xin Li*, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, Lidong Bing
Code ![]() |
|
![]() |
|
![]()

The Curse of Multi-Modalities: Evaluating Hallucinations of Large Multimodal Models across Language, Visual, and Audio
Sicong Leng*, Yun Xing*, Zesen Cheng*, Yang Zhou, Hang Zhang, Xin Li, Deli Zhao, Shijian Lu, Chunyan Miao, Lidong Bing
Breaking the Memory Barrier of Contrastive Loss via Tile-Based Strategy (Hightlight)
Zesen Cheng*, Hang Zhang*, Kehan Li*, Sicong Leng, Zhiqiang Hu, Fei Wu, Deli Zhao, Xin Li, Lidong Bing
Code |
![]() |
|
![]()

VideoRefer Suite: Advancing Spatial-Temporal Object Understanding with Video LLM
Yuqian Yuan, Hang Zhang, Wentong Li, Zesen Cheng, et al.
🧩 Image/Video Segmentation
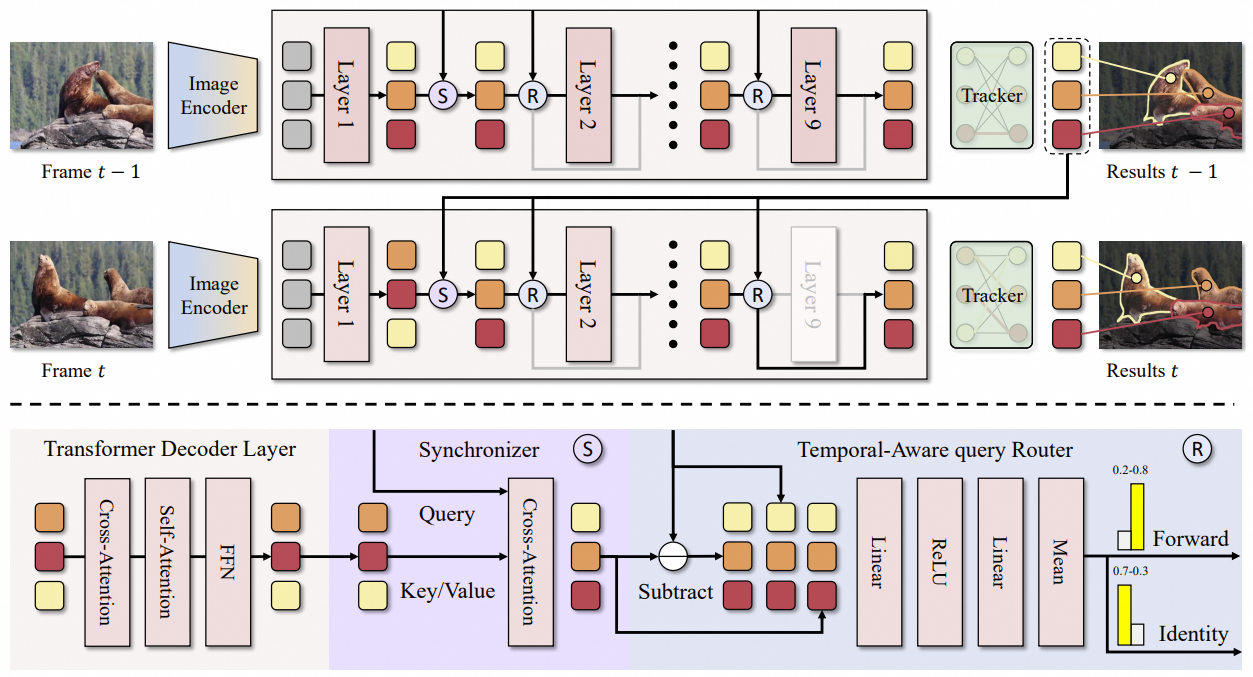
Temporal-aware Query Routing for Real-time Video Instance Segmentation
Zesen Cheng, Kehan Li, Yian Zhao, et al.
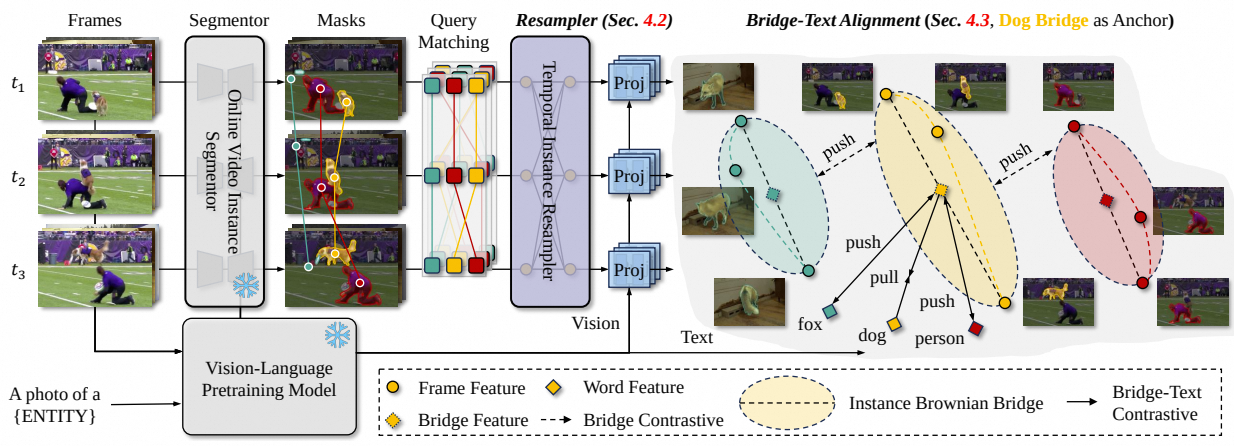
Aligning Instance Brownian Bridge with Texts for Open-vocabulary Video Instance Segmentation
Zesen Cheng, Kehan Li, Li Hao, Peng Jin, et al.
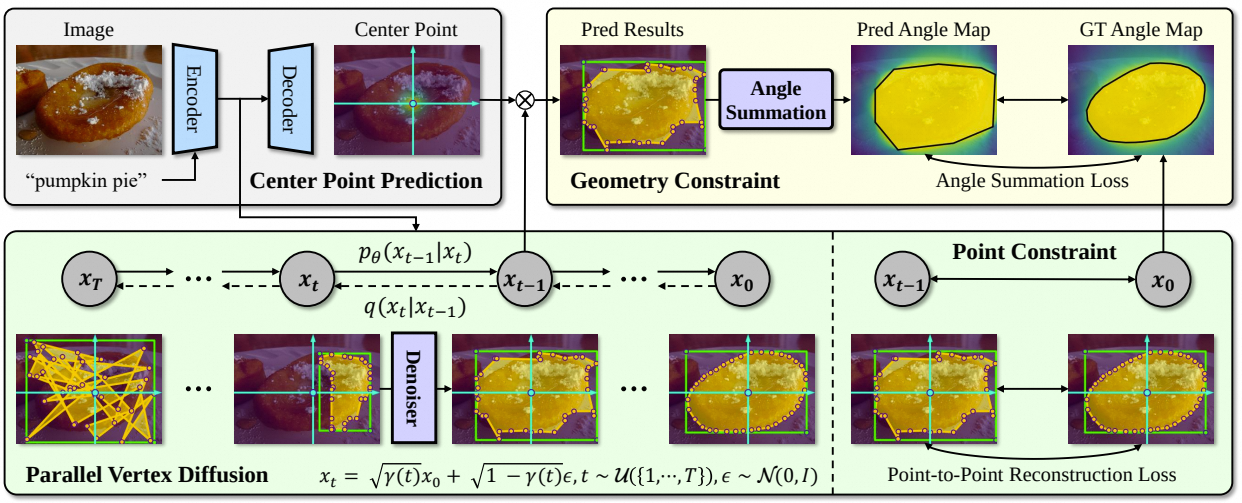
Parallel Vertex Diffusion for Unified Visual Grounding
Zesen Cheng, Kehan Li, Peng Jin, et al.
-
CVPR 2024(Hightlight) GraCo: Granularity-Controllable Interactive Segmentation
Yian Zhao, Kehan Li, Zesen Cheng, Pengchong Qiao, Xiawu Zheng, et al. | -
Neurocomputing 2024Hierarchical collaboration for referring image segmentation
Wei Zhang, Zesen Cheng, et al. -
ICCV 2023Multi-granularity Interaction Simulation for Unsupervised Interactive Segmentation
Kehan Li, Yian Zhao, Zhennan Wang, Zesen Cheng, Peng Jin, et al.

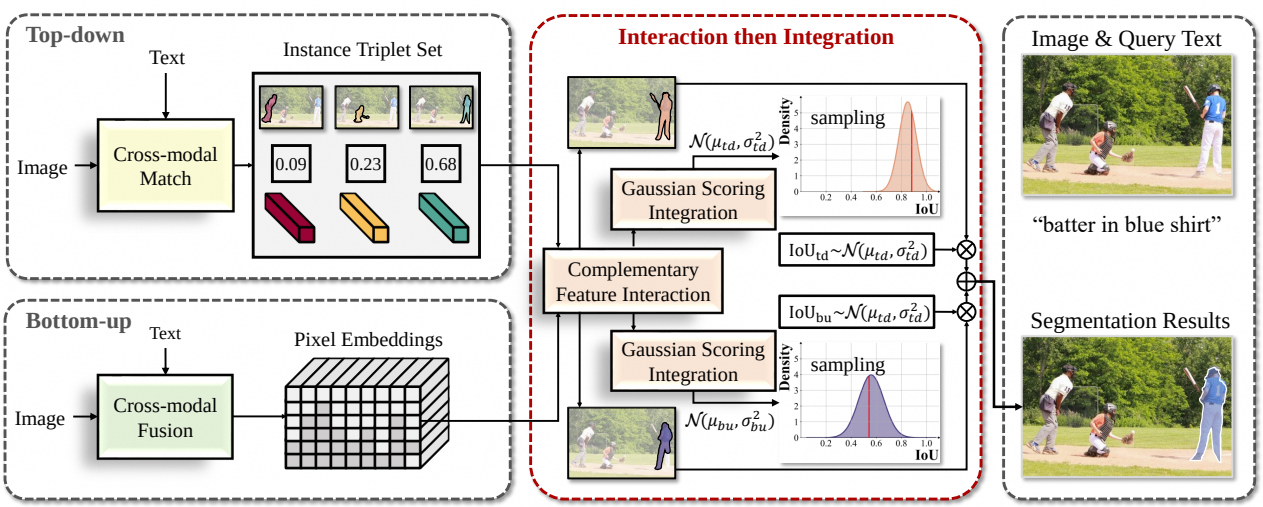
WiCo: Win-win Cooperation of Bottom-up and Top-down Referring Image Segmentation
Zesen Cheng, Peng Jin, Hao Li, Kehan Li, et al.
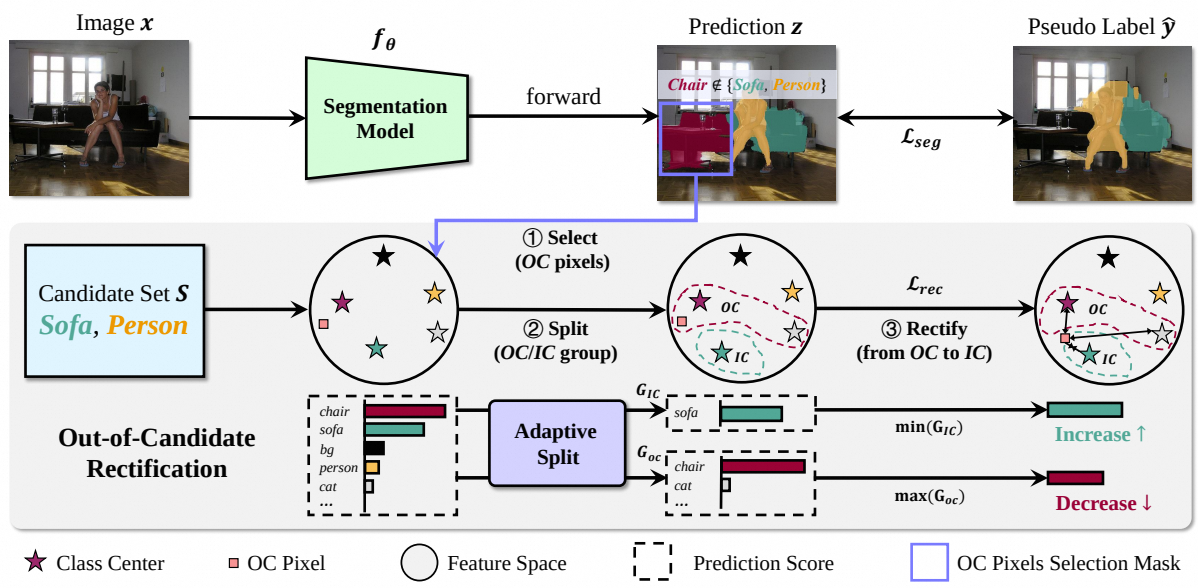
Out-of-Candidate Rectification for Weakly-supervised Semantic Segmentation
Zesen Cheng, Pengchong Qiao, Kehan Li, Siheng Li, et al.
-
CVPR 2023(Hightlight) ACSeg: Adaptive Conceptualization for Unsupervised Semantic Segmentation
Kehan Li, Zhennan Wang, Zesen Cheng, Runyi Yu, et al. -
CVPR 2023EDA: Explicit Text-Decoupling and Dense Alignment for 3D Visual Grounding
Yanmin Wu, Xinhua Cheng, Renrui Zhang, Zesen Cheng, Jian Zhang. | -
Medical Physics 2021Integrating multiple MRI sequences for pelvic organs segmentation via the attention mechanism
Sijuan Huang*, Zesen Cheng*, et al.

Others
ECCV 2024Local Action-Guided Motion Diffusion Model for Text-to-Motion Generation
Peng Jin, Hao Li, Zesen Cheng, Kehan Li, Runyi Yu, et al.ECCV 2024FreestyleRet: Retrieving Images from Style-Diversified Queries
Hao Li, Curise Jia, Peng Jin, Zesen Cheng, Kehan Li, et al. |PRCV 2023(Oral) Object-Aware Transfer-Based Black-Box Adversarial Attack on Object Detector
Zhuo Leng, Zesen Cheng, et al.ICCV 2023DiffusionRet: Generative Text-Video Retrieval with Diffusion Model
Peng Jin, Hao Li, Zesen Cheng, Kehan Li, et al. |IJCAI 2023Text-Video Retrieval with Disentangled Conceptualization and Set-to-Set Alignment
Peng Jin, Hao Li, Zesen Cheng, Jinfa Huang, et al.IJCAI 2023TG-VQA: Ternary Game of Video Question Answering
Hao Li, Peng Jin, Zesen Cheng, et al.


🥇 Honors and Awards
- 2023.10 Pingan Scholarship
- 2020.10 National Scholarship (Undergraduate) (Top 1%)
- 2019.10 The Second Prize Scholarship
- 2018.10 National Scholarship (Undergraduate) (Top 1%)
📖 Educations
- 2021.09 - present, Ph.D. Candidate, School of Electronic and Computer Science, Peking University.
- 2017.09 - 2021.06, Undergraduate, School of Electronic and Information Engineering, South China University of Technology.
💻 Internships
- 2025.01 - Present, Alibaba, Qwen Team, Hangzhou.
- 2024.01 - 2024.12, Alibaba, DAMO Academy, Hangzhou.
- 2021.03 - 2021.10, SenseTime, OpenMMLab, Shenzhen.